Rotatory Position Embedding (RoPE)
Introduction
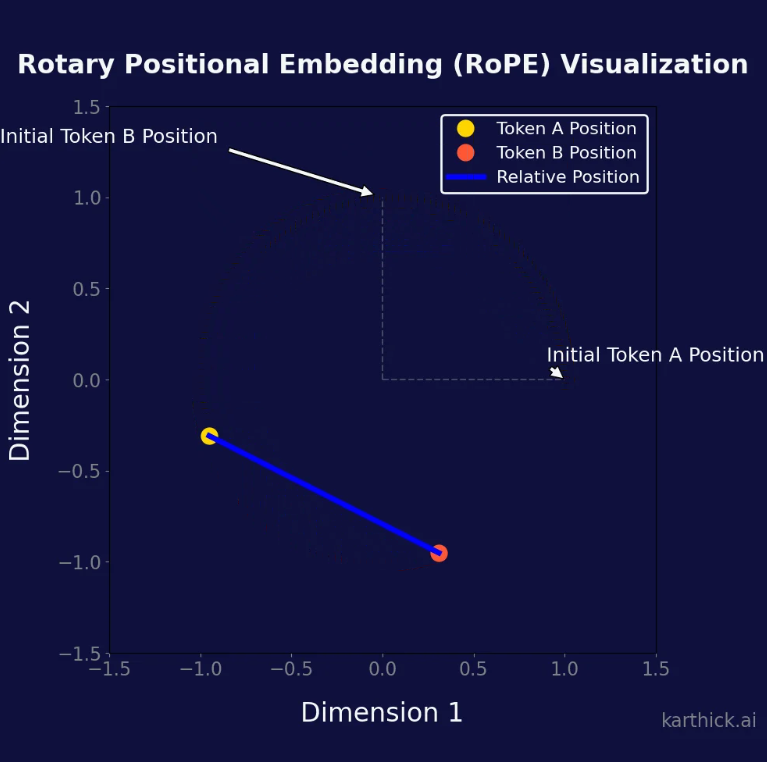
Positional embedding is a crucial part of transformer models such as BERT and GPT. Unlike traditional models such as RNNs or LSTMs that understand the order of input sequences through sequential processing, transformers consider input sequences as unordered sets. This approach improves computational efficiency and overall performance, but it doesn’t account for the natural order of tokens, which is essential for understanding text. This limitation exists because the transformer architecture relies on self-attention mechanisms, which are permutation-invariant. This means they treat all positions equally, regardless of the element arrangement in the sequence. Positional embeddings address this shortcoming by integrating the sequence’s order into the model’s inputs, enabling the model to maintain awareness of token positions. This understanding is essential for language tasks such as translation, generation, and comprehension, where changing the word sequence can drastically change sentence meaning. For example, “The cat sat on the mat” and “The mat sat on the cat” have the exact words but different meanings due to word order.