Fully Sharded Data Parallel (FSDP)
Introduction
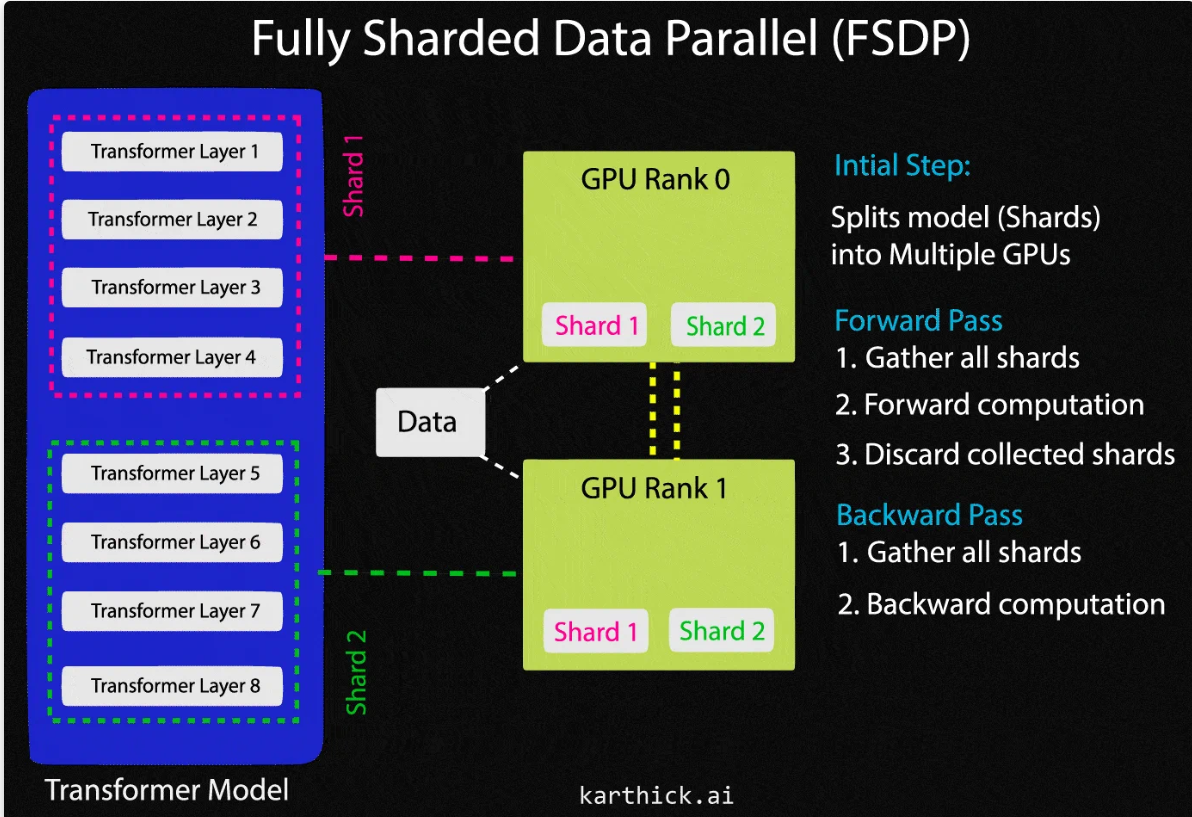
Training large language models on a multi-node, multi-GPU system can be a challenging task. Thanks to Fully Sharded Data Parallel (FSDP), a novel approach designed to enhance training efficiency by optimizing memory usage and scalability. It achieves this by sharding, or partitioning, the model’s parameters across all available GPUs in a distributed computing environment. Each GPU holds only a fraction of the total model parameters, reducing the memory requirements significantly compared to traditional methods. In this blog post, I will explain the mechanism behind FSDP and the practical code implementation of the fine-tuning Llama-3 8B model using FSDP+4Bit+PEFT.